Como coletar dados do Facebook com Facepager e R [funcionando]
Apresentação
Nos últimos anos, a extração de dados públicos do Facebook para pesquisa aplicada se tornou quase impossível. Em decorrência do escândalo do vazamento de dados pessoais, a plataforma fechou o acesso a posts públicos. O Netvizz, até então o aplicativo mais utilizado para baixar as publicações de candidatos, veículos da imprensa, movimentos sociais, entre outros, foi descontinuado.
Esse post tem dois objetivos: 1) contextualizar o momento atual das políticas de acesso aos dados das midias sociais; e 2) criar um passo a passo, ainda em funcionamento, para coletar publicações do Facebook. Para as atividades práticas, precisaremos de:
O que é
A extração de dados das mídias sociais se dá por meio do que se chama Interface de Programação de Aplicativos (do original Application Programming Interface – API). Provavelmente, você já ouviu falar das APIs. Basicamente, elas são canais de comunicação que permitem a usuários e aplicativos se conectarem aos sites para requisitar dados hospedados em seus servidores. Os aplicativos acadêmicos como o Netvizz e alguns softwares plenos de monitoramento nada mais são do que interfaces que se conectam às APIs e facilitam o processo de coleta de dados.
As APIs são, de um lado, um conjunto de comandos técnicos para realizar ações, mas também representam as políticas empresariais do Facebook para acesso ao seu banco de dados Caplan e boyd, 2018. Ou seja, as APIs tendem a ser alteradas constantemente, de acordo com as políticas corporativas do Facebook.
Contexto atual - APIcalypse
Assim, há questões de acesso aos dados que contrapõem o interesse acadêmico e as políticas dos provedores, que são as grandes empresas de tecnologia, chamadas de Big Tech. Nos últimos anos, esses procedimentos de coleta de informações mudaram radicalmente. Meirelles (2019) traçou o histórico das alterações nas APIs, indo de um nascimento otimista (2006-2010) ao contexto atual de desafios e restrições.
O acesso a essas fontes de dados é tutelado pelas empresas que gerenciam as plataformas de mídias sociais. No início de 2018, fustigado pelo escândalo do vazamento de informações pessoais pela Cambridge Analytica, o Facebook decidiu interromper a extração de posts de páginas públicas. Em 2013 e 2015, a gigante que monopoliza o mercado de mídias sociais já havia descontinuado os pontos de extração de dados de perfis pessoais. Dessa vez, resolveu submeter a coleta a um processo de revisão interna do próprio Facebook. Bernhard Rieder, criador do aplicativo mais usado no mundo para pesquisa no Facebook, o Netvizz, fez duras críticas às políticas da companhia, avessas ao escrutínio científico independente. Essa postura opaca diminui dramaticamente o accountability das práticas maliciosas nesse espaço.
Pesquisadores renomados escreveram um manifesto e colheram centenas de assinaturas contra o fechamento das fontes de dados do Facebook e do Instagram, plataforma controlada pela empresa.
Em mais uma peça importante da discussão acadêmica, Freelon (2019), liderança na virada computacional das ciências sociais, fez uma discussão sobre os desafios atuais. Ele argumenta que entramos numa sombria e incerta era da pesquisa pós-API. Com o colapso e fechamento generalizado das interfaces de coleta, seria necessário investir em outras metodologias de pesquisa e, eventualmente, implementar rotinas de raspagem de dados não sensíveis.
Os procedimentos atuais de coleta
A principal modificação do Facebook em 2018 foi determinar um estrito processo de verificaçao dos aplicativos para obter a chave de acesso à API. Um canal que era público e disponível para todos se tornou restrito, prioritariamente atendendo a demandas de anunciantes da plataforma. Com isso, o netvizz foi desautorizado e, consequentemente, desativado em setembro de 2019.
Jakob Jünger e colegas, conseguiu a permissão em dezembro de 2019.
Nesse tutorial, explicarei como integrar o Facepager e o R para automatizar os procedimentos de coleta de dados do Facebook. Devo notar, todavia, que a cessão de dados pelo Facebook está extremamente instável. Em sala de aula, aconteceu de alguns estudantes não conseguirem baixar na primeira tentativa e funcionar algumas horas depois.
Autorização pelo Facepager
O primeiro passo é conseguir a chave de autorização access_token pelo Facepager. Para isso, faremos os seguintes passos pelo app:
- New Database - cria um banco de dados
.dbno diretório; - Add Nodes - adiciona um nó para coleta de dados. Na caixa de texto, inserir
lulapor ser o username do ex-presidente no Facebook; - Login to Facebook - preencher com login e senha para obter a permissão
- Clicar em lula - às vezes não funciona se o node não estiver selecionado
- Clicar em Fetch Data - rodar a primeira coleta
- Copiar o status log - selecionar o texto de resposta e identificar o seguinte código
access_token=XXXX - Todo o texto depois de
access_token=é seu código de autorização. Copie para inserir noR
Seguir como na imagem:
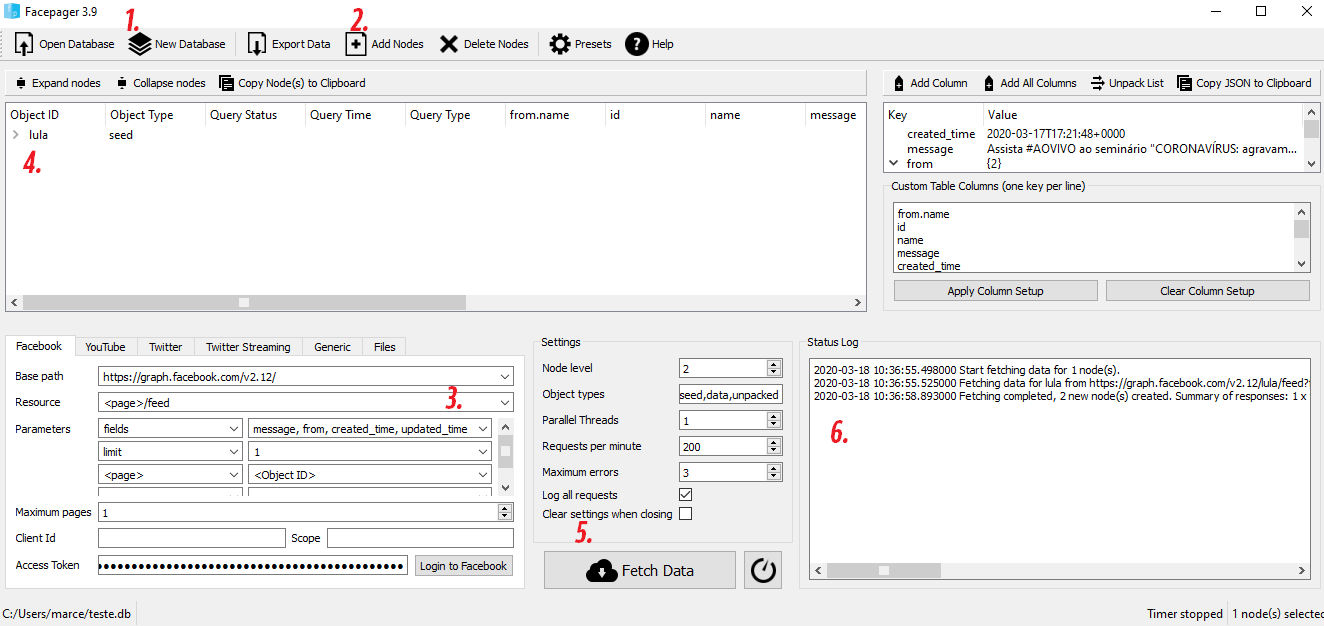
Finalizamos as etapas no Facepager. Caso não tenha familiaridade com o R, você pode realizar a coleta no software. Fiz um tutorial sobre isso.
Automatização pelo Rfacebook
A partir daqui, faremos as consultas direto pelo RStudio com nosso access_token vinculado ao Facepager na etapa anterior.
Precisamos instalar o excelente pacote Rfacebook, desenvolvido por Pablo Barberá
Clicar para exibir código
install.packages("Rfacebook") # pacote de conexao ao facebook
library(Rfacebook) # carregar o pacote na sessão atualEm seguida, criamos um objeto com o código do token
Clicar para exibir código
token <- "XXXX" # <- alterar o XXXX pelo seu códigoAgora, podemos rodar a função para acessar a API e coletar os dados
Clicar para exibir código
posts <- getPage(page = "estadao", # username da página - ex: facebook.com/estadao
token = token,
n = 10, # máximo de posts a serem coletados
reactions = F, # se baixa também as reações
since = "2019-12-01", # desde
until = "2019-12-30") # atéNo R, a varíavel posts guarda o retorno da extração.
Ela pode ser exportada para csv com o código:
Clicar para exibir código
write.csv2(posts, paste0("extração_face_", Sys.Date(), ".csv"))Pronto!
Se tudo ocorreu bem, ao final desse longo e complexo tutorial, teremos acesso à Public Posts API do Facebook. Atualmente, há poucos pontos de coleta. É possível extrair as postagens de páginas públicas, seus comentários, quais outras páginas elas seguem e o total de interações de links externos no Facebook.
Em meu Github, disponibilizei uma versão expandida dos códigos desse tutorial, contemplando:
Extração de múltiplas páginasAferição de medidas de interação de URLsBola de neve de following networkComentários
Caso alguma parte desse passo a passo não tenha funcionado corretamente, não deixe de mandar uma mensagem relatando o problema.
Considerações finais
A cada transformação da API, somos lembrados que as “redes sociais” são plataformas empresariais que detém um oligopólio sobre a gestão, uso e análise de nossos dados. Essas implementações visam, de um lado, proteger a privacidade dos usuários, e de outro, controlar ainda mais o acesso. Na prática, isso gera uma nova assimetria de poder entre quem pode ou não realizar pesquisas e se beneficiar dos insights de dados digitais, na medida em que empresas sempre poderão comprar os dados de algum revendedor, autorizado ou não, pelo Facebook.
O caminho para fazer pesquisa é aperfeiçoar os métodos de extração e de composição de amostra em universos digitais. Além disso, é fundamental debater a economia política da internet e aprofundar o conhecimento teórico sobre o direito a acesso aos dados. Principalmente para os fins de pesquisa, institutos acadêmicos podem se organizar para pressionar o Facebook para gerar APIs Universitárias, com acesso a dados anonimizados para fins de avanço da literatura especializada.
Marcelo Alves
Doutor em Comunicação e Professor do MBA de Big Data e Inteligência de Mercado
Comunicador e programador. Entusiasta de histórias contadas a partir de dados. Sou doutor pelo Programa de Pós-Graduação em Comunicação da Universidade Federal Fluminense (UFF).